
AI
LLM’s, AI modellen, ideeën, experimenten, verwondering en verbazing over AI.
- Oude posts van Punkey.com waren nog in het Textile-dialect van Pivot geschreven. Dat ging mee naar de archief site van Digging The Digital en zag er altijd onleesbaar uit. Codex maakte een plugin die foutloos zo’n 350 posts omzet van Textile naar HTML.
- Daarna maakte het een plugin om de afbeeldingen bij die posts weer terug te vinden en goed in de post te zetten. Door alle conversies en migraties waren die niet kwijt, maar onvindbaar. Nu niet meer. Jeuj!
- Om daarna nog de oorspronkelijke auteurs terug te zetten. We waren ooit met drie auteurs, maar ergens bij een migratie werd alles op mijn account gezet. Voor de geschiedschrijving wel zo netjes om de oorspronkelijke auteurs janneman en Da Huge in het archief weer op orde te hebben. Dank je wel Codex.
- En terwijl ik dit schrijf maakt Codex een nieuwe Micropub app waarmee ik eenvoudig verschillende soorten posts kan maken volgens het Micropub protocol. Claude Code had ooit een versie gemaakt maar ik had daar al het idee bij dat er teveel infrastructuur was gemaakt voor iets relatiefs simpels. Codex bevestigt dat na een analyse en is nu bezig om alles te herschrijven naar een meer eenvoudige browser extensie met bijbehorende Mac app. Zodat ik op mijn manier naar mijn blog kan posten.
- Met Skills ben jij de stuurman en Claude je copiloot.
- Met Agents ben jij de projectleider en Claude is je team.
- Werk wil delegeren
- Iets complexs hebt dat iteratie nodig heeft
- Parallel aan iets anders wil werken terwijl de Agent bezig is
- Wil dat Claude zelfstandig onderzoekt, aanpassingen doet, fouten corrigeert
- Meer specialisatie wil dan generieke hulp
- In je main window bent
- Wil dat Claude je wat slimmer maakt terwijl je aan het stuur zit
- Het werk synchroon kan (in- en uitvoer in één keer)
- Bereid bent om te wachten
- Jezelf de “denker” wil blijven en Claude de “assistent”
- De emailnotificaties goed laten werken. Iets met instellingen in de Docker container. Kan ik wel fixen.
- De mogelijkheid openstellen om reacties automatisch goed te keuren. Zal vast ergens een knopje zijn.
- De oude reacties importeren.
- Hackathons waar docenten en IT-mensen samen experimenteren
- Show Don’t Tell-middagen waar werkende prototypes worden gedeeld
- Terugkerende meetups waarin je de vooruitgang documenteert en vastlegt
Google's eigen idee van AI en advertenties. Op jouw computer.
Een ontluisterend artikel van Matthias Ott hoe Google plant om advertenties compleet te integreren in hun LLM-teksten.
When AI Mode gives you a list of recommendations, paid placements can now appear as items on that list. Google calls them “Highlighted Answers.” When you search for a product, Gemini writes a custom explainer for the advertiser, framed as objective advice about why this product “may be the right choice for you.” The language throughout is about being “helpful” and “building trust.” The mechanism is paid content inside AI-generated recommendations, written by the same model that’s supposed to give you neutral answers.
Ik raad je aan het hele stuk van Matthias rustig door te nemen. En een conclusie te trekken welke kant Google op beweegt in de huidige ontwikkelingen. Komende week geef ik samen met Erwin Blom een korte sessie vibecoding voor de NIMA, het onderwijsinstituut voor marketingprofessionals. In de voorbereiding besloten we om hier Google AI Studio voor te gebruiken, omdat het voor die groep mogelijk de makkelijkste route is. Geen gedoe met extra apps installeren zoals Claude of met meer besloten apps als Lovable aan de slag te gaan.
Ik denk dat we bij deze sessie ook wel kort stilstaan bij de ontwikkeling hoe Google LLMs ziet. En ik ben benieuwd hoe de discussie gaat zijn met marketeers.
In de comments van het artikel staat nog een saillant detail: De Chrome browser krijgt een ingebouwde 4GB Gemini Nano model. Een eigen lokaal LLM model. Wat in theorie bij je bestanden kan als je er toestemming voor geeft. Een LLM model van een bedrijf dat besluit om de grootste wijziging in 25 jaar te maken in hun businessmodel, waar het verdienmodel zit in de directe koppeling met jouw data uit je mail, kalender, navigatie, bestanden. Dat draait op jouw eigen computer.
Dus we krijgen bij een van de grootste techreuzen een compleet nieuwe interface die is “om te helpen” maar alleen tot doel heeft advertenties te pushen. Advertenties die er niet meer uitzien als advertenties maar verborgen zijn in een lijstje of gesprek. En dezelfde techreus draait een motortje op jouw eigen computer waar websites bij kunnen om iets mee te doen. Hoe vind je dat?
Lepelvragen
Stel jij wel eens lepelvragen?
Het antwoord op die vragen is altijd “Ja dat kan”
Er is een categorie vragen die ik vrijwel altijd krijg in mijn workshops. Ik zie ze ook in de chats van AI webinars verschijnen. Ik noem ze “lepelvragen”.
Ze beginnen altijd met “kun je dan ook…” en gaan over iets wat de vraagsteller eigenlijk niet voor mogelijk ziet. Kun je meerdere agents, of persona’s of skills tegelijk uitvoeren? Kun je je eigen skills laten maken? Zou ik mijn model naar keuze mijn WhatsApp-berichten kunnen geven om mijn tone of voice te bepalen? Zou het een app kunnen maken die mij elke dag drie vragen stelt om de dag goed te beginnen? Kan AI ook een website voor me maken die mijn planning toont in de stijl van Powerpuff Girls meets De Bauers?
Het antwoord is bijna altijd: ja dat kan.
Het kind in The Matrix geeft een mooie metafoor: “𝘛𝘩𝘦𝘳𝘦 𝘪𝘴 𝘯𝘰 𝘴𝘱𝘰𝘰𝘯.” De beperking zit niet in de tool. Die zit in het beeld dat je hebt van wat software mag kunnen.
Dat beeld is niets geks. Het stamt uit werken met software die precies deed wat er in de handleiding stond. Alles heeft vaste functies en vaste grenzen.
A.I. werkt anders. Er is geen lepel.
Een onverwacht voordeel met al dat vibecoden… tijdens het wachten kan ik rustig wat RSS-feeds lezen.
Een veelgehoord gevolg van het vibecoden met bijvoorbeeld Claude Code of Codex is dat je ineens veel meer projecten gelijktijdig kunt doen. En dus “productiever” bent. Nou doei, dat is dus niet waar. Mijn brein kan echt niet beter context-switchen omdat een bataljon AI-Freggles in mijn computer bouwt over 3 verschillende projecten. Ik moet dan teveel in de gaten houden en dat trekt mijn hersenpan eenvoudigweg niet.
Ik doe nu projecten die ik voorheen echt niet zelfstandig kon, die wel zorgvuldig en goed onderbouwd moeten gebeuren. Documentatie moet kloppen, ik werk het liefst heel stapsgewijs, ik lees de plannen van Claude zorgvuldig en wijzig waar nodig.
Als dat eenmaal allemaal klopt, dan gaat Claude wel aan de slag. Het kan dan prima 15 - 10 minuten zelfstandig delen van een project doen. In de tussentijd heb ik even pauze. Een mooi moment om wat RSS-feeds te lezen. Of een blogpost te schrijven.
Ik zie in mijn ooghoek dat Claude klaar is met stap 2 in fase 3. Ik moet weer gaan controleren en hem daarna verder laten werken.
Omdat ik recent een ChatGPT cursus gaf, moest ik toch even een Pro abonnement op de dienst nemen. Eerlijk gezegd, ChatGPT is niet mijn favoriet. Want Sam Altman en de schuivende prioriteiten die ze hebben als bedrijf. Maar bij zo’n abonnement krijg je Codex, wat een alternatief is voor o.a. Claude Code. Ik zit daar nu een ochtend mee te werken en ik moet eerlijk zeggen, het geeft prima resultaten! In nog geen anderhalf uur tijd heeft Codex me geholpen bij een paar langlopende projecten die ik steeds uitstelde
Is dit een tip om nu Codex te gaan gebruiken in plaats van Claude Code? Niet direct. Over een paar dagen is dit abonnement weer verlopen en stop ik met Codex. Maar het was een mooie aanleiding om weer wat achterstallig archiefwerk op te lossen en te testen hoe Codex werkt. Prima dus. Maar ja, het blijft OpenAI achter de schermen.
Cognitieve soevereiniteit, waar stopt mijn denken en begint de machine?
Eigenlijk zijn al die artikelen die ik door AI laat maken helemaal prut. Ik heb ze in het verleden echt wel gemaakt. Nog steeds laat ik trouwens geraamtes en opzetten samen met AI maken. In het verleden liet ik dan een AI model een compleet artikel schrijven. Het heeft toegang tot mijn eerdere blogposts, het heeft een skill dat mijn tone of voice nabootst. Juist, nabootst. Want ik ben het niet zelf. Het zijn regels waarmee ik een poging doe om mijn schrijfstijl te vangen. Dat is nog niet zo makkelijk. En nee, niet omdat ik nou zo’n prozaïsche, uitgesproken, unieke schrijfstijl heb. Maar omdat er veel van mijn eigen denkvermogen in het schrijven zit, waar de woorden direct van het hoofd naar de handen gaan. Bij sommige zinnen denk ik weinig na over de exacte flow en ga ik gewoon aan de slag.
Zoals de vorige twee zinnen. Niets aan gewijzigd, eenvoudig vanuit de gedachten, op dat moment voelde het goed, ram-bam op het scherm. En ook zo’n woord ram-bam. Daar zal een LLM echt niet zelf mee komen. Het heeft wel een regel, en ik quote:
Frank schrijft op B1-niveau: helder, toegankelijk, inclusief. Zijn Nederlands klinkt als gesproken taal op papier. Contracties en spreektaal. Gebruik informele vormen: zo’n, best wel, eigenlijk, ’t, wat (in plaats van “iets”). Dit maakt tekst luchtig. Een tekst zonder contracties klinkt als een overheidsbrief, niet als Frank.
Maar goed, ik wil het niet over mijn schrijfstijl hebben. Maar over een term die ik nog niet kende. En die alles te maken heeft met hoe ik schrijf, en waarom ik schrijf: Cognitieve Soevereiniteit. Eigenaarschap over je kennis en kunde. Zoals die posts die ik met AI heb gemaakt. Je zou kunnen zeggen, je doet het helemaal verkeerd! Slechte skills, verkeerde prompt, je prutst maar wat aan. Misschien. Maar stel dat ik die posts beter zou maken met scherpere prompts. Als ik er meer tijd in had gestoken om die tone of voice waterdicht te maken. Wat zou ik er dan zelf van leren? Niks. En dat is het punt. Dat is waar je eigenaarschap over je kennis en kunde om de hoek komt kijken.
Wat ik bedoel met cognitieve soevereiniteit
Er is een hoop te doen over digitale soevereiniteit. Los komen van Amerikaanse BigTech. Meer Europese oplossingen en lokale AI modellen die op een eerlijke manier zijn getraind en opgebouwd. Minder afhankelijkheid van grote partijen als Google, Microsoft en OpenAI, waarbij we de technologie, hardware en software in eigen handen hebben.
Maar hoe zit dat met je eigen kennis en kunde.
Het is één ding om je digitaal minder afhankelijk te maken van BigTech. Maar dit gaat een laag dieper.
Cognitieve soevereiniteit gaat er voor mij over wie het voor het zeggen heeft in jouw hoofd. Hoe jouw denken wordt gestuurd, waar het eigenaarschap zit van jouw eigen denken. Of je zelf kritisch kunt denken, of je het vermogen hebt om goed te kunnen redeneren. En of je daadwerkelijk eigen gedachten kunt maken. Klinkt simpel, maar het kan verrassend complex zijn. Want zij jou gedachten altijd wel van jou? Hoe trek je de grens tussen wat je uit een LLM krijgt en wat je zelf uit boeken haalt?
Waar het volgens mij mee te maken heeft, is dat je bewuste keuzes maakt welke tools je inzet voor welke actie. Het betekent dus niet dat je als een ware Luddiet je afschermt van technologie. Of dat nou AI is, spellingscontrole of een rekenmachine. Het gaat erom dat jij bewust en onderbouwd de scheiding maakt: waar stopt je eigen denken en waar kan een machine het deels overnemen? Je kunt denken aan Digitale Geletterdheid, al gaat dat meer over “het handelingsvermogen om informatie te vinden, te beoordelen, samen te brengen en zo bepaalde vragen te beantwoorden”. Maar met Cognitieve Soevereiniteit gaat het veel meer over het vermogen om zelf aan het stuur te zitten wanneer je welke informatiebronnen gebruikt. Dat je weet waarom je dat doet. En dat je in staat bent om je eigen gedachten te vormen rondom de onderwerpen waar je over nadenkt. In plaats van het voornamelijk uit digitale bronnen te halen.
“Maar eigen denken bestaat toch niet?”
Dit is een tegenargument dat ik al wel eens hoorde en dat blijft hangen. Critici verwijzen naar cognitiewetenschappers als Daniel Kahneman, die in Thinking, Fast and Slow laat zien hoe ons brein vooral werkt op Systeem 1: snel, intuïtief, associatief. Systeem 2, het bewuste en redenerende deel, zetten we maar zelden echt aan. Of ze halen filosoof Andy Clark erbij, die in Surfing Uncertainty stelt dat het brein in de basis een voorspellingsmachine is. Precies wat een taalmodel ook doet, zeggen ze dan. Alles wat ik denk komt uit boeken die ik las, gesprekken die ik voerde, films die ik zag. “Eigen” denken is een illusie, dus waarom zouden we doen alsof het iets bijzonders is?
Ik snap het argument prima. Maar het mist één ding: het verschil tussen invloeden hebben en je werk uitbesteden.
Mijn denken is zeker gevormd door wat ik heb gelezen de afgelopen 30 - 40 jaar. Van school tot werk en mijn interesses. Fictie en non-fictie. Online en offline. Maar wat ik dan vervolgens met die invloeden doe, hoe ik ze combineer, welke ik op de voorgrond zet en wat ik wegfilter, dat is een proces dat in mijn hoofd plaatsvindt, met mijn beperkingen en mijn voorkeuren. Op het moment dat ik dat hele proces overdraag aan een model, gebeurt het ergens anders. Het maakt voor het resultaat misschien weinig uit. Voor wie ik daarna ben wel. Ik heb de gedachten niet doorleefd. Ik heb ze niet zelf gevoeld, gevormd en op een rij gezet. Ik heb het uitbesteed aan iets anders en ik accepteer wat er uit komt. Dat is een wezenlijk verschil voor ons mensen.
Waarom is het belangrijk?
Omdat je de soevereiniteit, dat eigenaarschap pas mist als je het niet meer hebt. We beschouwen onafhankelijkheid vaak als een gegeven. Het is er, dus het is prima zo. Maar op het moment dat het er niet meer is, dan missen we het pas. En dat is moeilijk te herstellen.
Ik worstel er enorm mee. Ik merk soms echt dat mijn denk capaciteit afneemt. Ik heb soms moeite om zinnen “rond” te maken, paragrafen op te bouwen, een denkpatroon te ontwikkelen rondom een thema. Dan grijp ik te snel naar een AI-model om me op weg te helpen.
Ik praat het goed voor mezelf met een “oké, dan heb ik een beginnetje”. Maar eigenlijk ligt er al best veel uit zo’n model. Dan herschrijf ik het, zonder dat het helemaal van mezelf is. Dat gemak kan heel snel de overhand nemen en dat vind ik lastig.
“Wie heeft de tijd voor die denk-luxe?”
Maar inderdaad, waarom zou ik vier uur worstelen met een paragraaf die een model in een paar minuten oplevert? Is dat autonomie? Is dat altijd nodig? Ik denk het eigenlijk niet. Voor een rapport van een data-analyse, een mailtje dat structuur mist, een eerste opzet voor een offerte. Gebruik AI er bij om de opzet te maken. Ik vind dat je dan weinig verliest aan eigenaarschap als je delen hiervan uitbesteedt.
Maar wat met het werk waar het denken het product is? Een blogpost. Een hoofdstuk waarin ik een idee uitwerk dat ik nog niet helemaal scherp had. Een gesprek met een klant over een richting. Dan is tijdwinst echt geen winst voor me. Want die tijd heb ik nodig om het denken plaats te laten vinden. Dat is die afnemende capaciteit waar ik het net over had. Als ik die denktijd wegoptimaliseer in een model, wat win ik er dan mee? Ik krijg geen nieuwe creatieve inzichten.
“Maar voor mensen die niet zo kunnen schrijven als jij…”
Dit artikel heb ik ook samen met AI gemaakt. Ik kom zo nog op de werkwijze. Het model (Claude Cowork Sonnet 4.6) gaf me een inzicht waar ik nog niet bij had stilgestaan. Ik ben in een positie dat ik kan schrijven. Ik heb al een oeuvre opgebouwd, ik kan mijn gedachten redelijk goed op papier zetten. Maar hoe zit dat met iemand met dyslexie, met ADHD, een taalachterstand of weinig opleiding? Voor hen kan AI vaak de eerste keer dat ze hun gedachten goed en geordend tot uiting kunnen brengen. Ik kan me niet voorstellen hoe bevrijdend dat moet zijn. Moeten zij dan ook soeverein zijn en maar beter zelf leren nadenken? Lijkt me niet toch? Ik heb een privilege waarin ik deze vraag over cognitieve soevereiniteit kan stellen en over kan denken. Dat is niet aan iedereen.
Cognitieve soevereiniteit gaat voor mij dan niet over “doe alles zelf” of “blijf ver weg van AI”. Het gaat over de bewuste keuze waar jouw denken ophoudt en de machine begint. Voor de één betekent dat: gebruik AI om de woorden te vinden die jij in je hoofd hebt maar niet op papier krijgt. Voor de ander betekent het: gebruik AI niet om de gedachten zelf te bedenken. Het verschil is wie het denkwerk doet, niet wie de typisten zijn.
De spanning in mijn eigen werk
Deze blogpost heb ik met AI gemaakt. Ik heb een aantal sites geopend over het onderwerp en heb ze gelezen. Op basis van wat ik las ben ik gaan praten tegen de computer. Ik maak in Obsidian een document waar ik met Spokenly begin te praten over het onderwerp. Wat is Cognitieve Soevereiniteit volgens mij. Waarom is het belangrijk, wat zijn de tips om je autonomie te bewaken.
En al pratende meander ik allerlei kanten op over mijn twijfels van werken met AI. Dat ik het een lastige grens vind waar AI stopt en je eigen denken start. Hoe ze elkaar beïnvloeden.
Die bijna 1700 woorden heb ik aan verschillende modellen gegeven: Claude Sonnet, Google Gemini en lokaal aan Google Gemma. Met de opdracht om de gedachten die ik heb uitgesproken te ordenen zodat ik er een blogpost van kan maken. Om er een logische opbouw in te maken. De exacte opdracht die ik aan elk model heb gegeven, samen met het markdown bestand van mijn uitgesproken gedachten:
In dit document vind je een lange transcriptie van de gedachten die ik heb over het onderwerp cognitieve soevereiniteit. Ik wil dat je deze gedachtes ordent op een manier zodat ik er een logische blogpost van kan maken. Ik wil dat je zoveel mogelijk de originele teksten gebruikt in plaats van het zelf te interpreteren. Maak er wel kopjes van hoe ik een blogpost zou kunnen opzetten.
Ik kreeg drie versies die ik weer lokaal heb opgeslagen. Verschillend maar er zaten wel veel dezelfde denklijnen in. Google Gemma was het minst in de output. Daarna Gemini, Claude kwam met de beste opzet. Wat niet zo gek is, ik werk daar dagelijks in, dus het model heeft veel kennis over me, weet de instructies en kan net iets verder gaan dan de andere modellen.
Maar goed, daarna vroeg ik:
Geef me eens tegenargumenten als een ware AI-utopist bij een artikel over dit onderwerp
Om vervolgens met al die argumenten, met de drie versies en de oorspronkelijke transcriptie een nieuwe versie te maken. Dat is wat je nu leest. Inmiddels heb ik zo’n 80% herschreven. De opbouw is nog wel uit het origineel, evenals de keuze voor de tegenargumenten. Maar vrijwel alle zinnen en gedachtensprongen heb ik herschreven. Omdat ik al lezende merkte dat ik er zelf nog een keer een logisch verhaal van moest maken. In mijn eigen woorden. Niet uit mijn Tone of Voice handboek. Bij een offerte zou dat echt anders zijn. Maar bij deze post is AI voor mij de arbeider die mijn versplinterde gedachten weer bij elkaar brengt, ze in een volgorde zet waardoor het voor mij werkbaar wordt én die ik kan uitdagen om een andere rol aan te nemen, zodat ik mijn denken over het onderwerp krachtiger kan maken.
Vijf praktische tips om je autonomie te bewaken
Wat voor mij heeft gewerkt om al dit denken en schrijven over cognitieve soevereiniteit in goede banen te leiden:
Spreek met jezelf af dat je niet alles laat schrijven. Doe de eerste dingen zelf, zonder AI. Of in elk geval, zet AI niet meteen aan de slag. Ik had met pen en papier een mindmap kunnen maken, maar ik koos er voor om het in te spreken. Ik heb eerst zelf nog wat nagedacht over het onderwerp. Wat vind ik er van?
Daarna liet ik een AI model alles ordenen, aanvullen, tegenspreken en me vragen stellen. Ik let op hoe ik daar zelf op reageer. De opmerking van de AI-utopist over het privilege van al kunnen denken en schrijven verwonderde me, omdat ik er nooit over had nagedacht. Een typisch kenmerk van in een privilege leven. Dat heeft me geholpen. Ik wilde ook per se dat mijn uitspraken in het hele samenwerken worden gebruikt. Niet een herschreven of vertaalde versie.
Ik liet AI dus tegenargumenten maken. Wat klopt er niet? Welke perspectieven ontbreken? Wie heeft er belang bij dat ik iets op deze manier doe? Ik heb liever een sparringpartner dan een ghostwriter. Deze blogpost is daar dus een voorbeeld van zoals ik al schreef. De vragen die je hier ziet voorbijkomen, kreeg ik van Claude die als AI-utopist los ging op het artikel.
Gebruik meerdere AI-modellen. Vergelijk de output, laat ze elkaar bevragen en beoordelen. Ik probeer vaker een lokaal model te gebruiken. En ik bedacht me dat ik Mistral helemaal ben vergeten in deze oefening.
Plan je eigen denkblokken in. Ik heb deze post over een zaterdag samengesteld. Tussendoor wat andere dingen gedaan, maar wel nagedacht over de materie. Ben ik het er na het herlezen nog steeds mee eens. Wat vind ik er van. Waar besteed ik iets uit? Zoals ik al zei, bijna 80% van de versie die Claude schreef is compleet herschreven.
Het is geen ‘human in the loop’
Het is helemaal niet erg om iets uit te besteden aan AI of aan andere tooling. Maar je moet daarbij steeds bewust blijven: wat vind ik ervan? Wat doe ik hier zelf aan?
Dat heeft niets met human in the loop te maken. Dat is de term die je heel snel tegenkomt, maar daar gaat het wat mij betreft steeds meer om “controleer wat er uit een model komt”. Waar ik het over heb is daadwerkelijk eigenaarschap nemen op het eindwerk, op de redeneringen, op de kennislagen die ontstaan. En dat je als human in the loop ook tot de conclusie kunt komen dat je veel weer opnieuw kunt doen. Zoals ik nu doe.
“Maar de algoritmes sturen je toch al?”
Tot slot een tegenargument dat me werd voorgelegd en wat ik zeker interessant vind.De algoritmes van TikTok, Instagram en YouTube sturen ons denken al jaren. Dat doen ze veel agressiever dan een AI-model en we gaan er in mee. We weten het, we leggen ons tijdverdrijf in de handen van een algoritme dat tot doel heeft om je langer bezig te houden. Een AI-model waar je bewust mee in gesprek gaat is in die vergelijking misschien wel een tegengewicht.
Daarom worstel ik zo met die discussies over “AI is gevaarlijk” of “blijf weg bij modellen”. Of de discussies over het ethische, sociale en klimaat-aspect. Voor mij gaat het om een actief en bewust gebruik van de instrumenten die er zijn. De instrumenten helpen me om mijn gedachten beter te ordenen. Je zou denken dat ik na 25 jaar bloggen dat toch prima moet kunnen maar niets is minder waar. Of dat nu komt door die AI modellen of dat het al langer speelt, ik weet het niet zeker. De invloed is er zeker. En ik heb de keuze hoe ik er mee om ga.
En nu?
Ik kende de term zelf nog helemaal niet maar ik begrijp de achterliggende gedachte maar al te goed. Ik wist alleen niet dat er een woord voor was. Waar het voor mij op aankomt, ik wil me niet afsluiten voor de nieuwe technologie, maar weten waar mijn eigen denken ophoudt en de machine begint, en die grens bewust bewaken. Da’s knap lastig. Maar ik vind het interessant.
Kunnen Vintage Language Modellen de toekomst voorspellen?
Als je meer wilt leren hoe AI de mensheid echt vooruit kan helpen, kijk dan de fantastische documentaire The Thinking Game. Het vertelt over Demis Hassabis en zijn levenswerk om artificial general intelligence te realiseren. Hoe hij DeepMind start en uiteindelijk een Nobelprijs wint met AlphaFold; een AI-systeem dat met hoge nauwkeurigheid de 3D-structuur van eiwitten voorspelt op basis van hun aminozuurvolgorde.
In de documentaire doet Hassabis een uitspraak die me is bijgebleven, en die ik eerlijk gezegd zelf ook wel eens gebruik: “Als een LLM is getraind met data die niet verder gaat dan 1911, kan het dan zelfstandig tot de relativiteitstheorie komen, zoals Einstein deed in 1915?”
Immers, als het dan zou kunnen, zonder toegang tot data na 1911, dan zou dat betekenen dat een model zelfstandig patronen kan herkennen, origineel wetenschappelijke gedachten kan hebben en een abstractieniveau heeft om zelfstandig nieuwe kennis te genereren.
Je kunt je afvragen of de bouwstenen van de relativiteitstheorie al niet besloten lagen in de data van voor 1911. Einstein had die bouwstenen ook, en wist ze op creatieve wijze bij elkaar te brengen om tot een compleet nieuw inzicht te komen. Dus als een model dat doet, is het dan echt een unieke nieuwe gedachtengang, of is het een een geavanceerde vorm van patroonherkenning die we wel vaker zien bij LLM’s? We zouden het binnenkort zelf kunnen ontdekken, want er is nu Talkie, een Vintage Language Model (ik hou nu al van die term) en getraind met data tot uiterlijk 1930. De makers bouwen voort op bestaande experimenten van zulke modellen.
Het is nog onduidelijk of het inderdaad zelfstandig tot ontdekkingen als de relativiteitstheorie kan komen, maar ondanks dat vind ik zulke ontwikkelingen interessant om te zien. Allerlei kleine modellen die je eenvoudig op je eigen computer of telefoon kunt gebruiken. Handig voor de Steampunk Cosplay scene die net wat meer moderne technologie willen inbouwen!
De stand van alle dingen en andere zaken
Zelfs na 25+ jaar twijfel je of je nog wel wat hebt te vertellen op je eigen site. Ongeacht wie het leest of welke eeuwigheidswaarde het heeft. Elke week nam ik me voor om gewoon weer eens de tijd te nemen om gedachten te delen. Om ideeën te testen. Om dit kleine platform als laboratorium te zien waar ik mijn halve schrijfsels en vage ideeën op gooi om te zien wat resoneert. Maar het gebeurt gewoon niet. Sinds februari zijn mijn dagen zo gevuld met ander werk, dat de vrijheid van het schrijven op mijn eigen platform als eerste van de kar valt.
De twijfels
Dat is zo zonde, want ik weet dondersgoed wat de waarde van je eigen platform is. Van het samengestelde en opbouwende effect van showing up en hiermee je eigen publiek op te bouwen. Te houden. Te voeden. Ik zie alle Substacks, LinkedIn-contentstrategieën en YouTube-series en denk, waarom krijg ik me er toch niet toe gezet?
Is het te veel werk? Heb ik er wel zin in? Weet ik zeker dat het iets op kan leveren, niet op de langere termijn, maar in het hier en nu?
Heb ik het wel nodig? Mijn agenda is voor nu redelijk OK gevuld. Ik ben geen financieel en zakelijk orakel die in één oogopslag voorziet wat er komt en wat dat onder de streep betekent. Maar het voelt goed voor de komende tijd. Is dat voldoende? Nou nee. Moet ik dan nu een contentstrategie opstarten en meer posten op LinkedIn om die zichtbaarheid maar goed te krijgen? Of gooi ik dit hele platform (weer) om, zodat ik me meer focus op de drie gebieden die er voor mij nu toe doen: AI, een creatieve mindset en Persoonlijk Kennis Management. Haal ik de onnodige posts uit de lijsten, van de frontpage, en gebruik ik mijn blog weer als vehikel voor mijn onderneming?
Logica
Het is het meest logische. Maar tegelijk weet ik dat het bereik nu weer klein is. Ik hou van elke lezer die hier komt, de meesten ken ik volgens mij persoonlijk. Met zo’n 400 bezoekers per maand is het geen stil theater hier, maar om nou te zeggen dat je over de koppen kunt lopen…
Hoe dan ook, het plan was om een overzicht te geven wat ik zoal de afgelopen maanden heb uitgespookt en nu is het toch mooi een train of thought geworden over mijn aanwezigheid op dit blog en op andere plekken.
Maar wat heb ik dan zoal gedaan de afgelopen tijd? Als ik het zo op een rij zie, mja, ik ben best wel bezig geweest. Logisch dat hier publiceren er even bij inschoot. Zal ik dan hier en nu een pinky-promise doen om wat meer te delen? Al zijn het korte schotschriften, halve gedachten, links naar anderen. Niet alles ver uitgewerkt, maar langzaam weer een oeuvre opbouwen waar ik tevreden naar kan terugkijken.
Iets met AI…
Het is geen verrassing dat de meeste tijd heeft gezeten in AI. Ik geef open workshops Claude Code bij Wonders of Work (19 juni is de nieuwe editie) en betaalde workshops Claude Code voor maximaal 8 ondernemers. Die lopen allebei goed en zitten altijd vol. Ik word er blij van als ik bij elke workshop de kwartjes hoor vallen, de lampjes aangaan en de ogen oplichten. Als ik zie dat mensen beseffen wat een krachtig instrument ze in handen hebben en dat ze er zelf mee aan de slag kunnen.
Ik blijf in een vreemde spagaat zitten over de ethische, maatschappelijke, milieu- en privacyaspecten van AI. Ik erken dat ze er zijn, ik weet dat ik bijdraag aan deze aspecten en ik kies er voor om er met bijvoorbeeld workshops en leergangen anderen te helpen hoe zij ook met AI aan de slag kunnen.
Liefst zie ik modellen als Mistral, en modellen die je lokaal op een eigen machine kunt uitvoeren, snel verbeteren, maar daar zijn we nog niet. Ik heb nu in elk geval een maand Mistral Pro genomen om zelf te ervaren hoe het werkt. Net als ik recent met GreenPT heb gedaan.
Iets met een boek…
Hoe gaat het schrijven van CreativeNotes? Er zit al meer vaart in. Ik kan zo nu en dan wat kleine momenten vinden om een tekst te herzien, wat paragrafen te herschrijven, een transcriptie opnieuw te doen (want de modellen zijn nu zoveel beter!) en om bij te lezen over het onderwerp. Het gaat nog niet op het tempo dat ik zou willen. Hier komt ook de dagindeling en mijn energieniveau bij kijken. Ik merk dat ik maar een beperkt aantal lepels energie heb op een dag die ik kan verdelen. In de avonden, na een werkdag, zijn de lepels op. En kan ik niet meer schrijven of nadenken over de materie.
Maar in maart kwam wel het boek Verder met Obsidian uit. Geschreven door Martijn Aslander en mijzelf. En waar ik hier nog nooit over heb geschreven. Idioot! Hoe kan dat nou?!
Het zit hem wederom in de focus die ik het gaf toen het uitkwam. We schreven dat boek in een paar weekenden in november en december. Met behulp van AI-research en AI-editing. Dat ging heel snel, waardoor ik na het inleveren van het manuscript de aandacht verloor. De lancering was tijdens de PKM Summit, en daarna gingen Martijn en ik weer door met andere onderwerpen.
In tegenstelling tot Verder met Obsidian zal CreativeNotes veel meer een langetermijnproject zijn. Niet alleen het schrijven, maar net zo goed alles wat er na komt. De promotie. Het platform. De mogelijke vervolgserie die ik in mijn hoofd heb. Ik moet alleen nog een goede naam vinden voor het boek. Denk ik.
En al die andere dingen dan?
In maart eindigde de eerste serie van onze Pilot Informatie Autonomie, een onderzoekslab naar de verborgen kosten van onze informatiegewoonten.
Veel kenniswerkers zijn gewend om hun werk en kennis op te slaan in bestandsformaten en systemen die niet primair gemaakt zijn om informatie snel te verbinden, te verspreiden en te vinden. We werken niet efficiënt met onze digitale middelen, iets waar we met Digitale Fitheid Academie bij helpen om dat te verbeteren. De pilot was een onderzoekstraject waarbij we bekeken hoe we de dagelijkse informatiebehoefte van kenniswerkers kunnen verrijken met een werkwijze die minder kost en meer oplevert.
De eerste resultaten zijn inmiddels bij de deelnemers bekend en we starten eind april met een tweede pilot die tot eind 2026 loopt. Ik ben hier wederom bij betrokken.
Daarnaast werk ik meer samen met Annedien Hoen en Jefta Bade in het Ride The Dragon council. Deze drie-eenheid helpt leiderschapsteams om te navigeren in een wereld waar langetermijnstrategie minder waarde heeft. Wij ontwerpen met het leiderschapsteam een bruikbaar en navigeerbaar gedachtengoed en brengen dat tot leven in concrete handelingsbekwaamheid, artefacten die in de organisatie voor beweging zorgen en praktische inzichten waar je direct mee aan de slag kunt.
Met Mark de Kock help ik leidinggevenden en managementteams om richting te geven op het punt waar strategie concreet moet worden. Met een focus op finance, zorg en vastgoed.
Ik geef korte AI-workshops bij GetOn Academy voor MKB-ondernemers. Dit zijn basiscursussen in een vast format, vooral bedoeld als je echt nog nooit iets met AI hebt gedaan.
Tijd voor hobbies?
Eerlijk gezegd, te weinig. Ik wil het linoprinten weer oppakken maar neem er de tijd niet voor. Ik zit dan liever even rustig in de tuin of maak een wandeling. Lezen kom ik te weinig aan toe, al heb ik recent wel met veel plezier Steven Johnson’s Where Good Ideas Come From gelezen, evenals de laatste boeken van Arjan Broere: De AI-Gewoonte en Slimmer Prioriteren. Maar een goede roman? Nee, daar komt het gewoon niet van.
Dus…nu? Stug verder gaan. Blijven bloggen. Blijven schrijven. Dingen proberen. Mooi werk maken. Mijn gezin onderhouden en mijn dagen waardevol inrichten. Soms met een workshop, soms met schrijven, soms met in de tuin zitten.
AI Schrijfpatronen
Dat is geen nieuwe gewoonte. Dat is een evolutie in je schrijfwijze.
Denk ik. Geen idee. Ik werk aan een tekst voor CreativeNotes. Alle teksten schrijf ik zelf, ondersteund door een geraamte en opbouw die ik met Claude samenstel. De zinnen komen uit mijn hoofd en handen.
Ik betrap me er net op dat ik de zin schrijf “Dat doen we niet uit gewoonte, dat is een teken dat papier écht anders werkt”
Hmm… Schrijf ik die zin op deze manier omdat het zo’n opvallend patroon is in AI teksten die ik té vaak tegenkom? Of schrijf ik deze constructies vaker en valt het me nu op omdat het een AI patroon is? Ik kan me er niet toe brengen om deze zin in het boek te laten. Zelfs niet in de eerste draft. Het is een te opvallend patroon van deze tijd en breekt het vertrouwen met de lezer. Als die mediawijs genoeg is zal die het patroon herkennen. En daarmee de vraag stellen, wat is door AI modellen geschreven en wat is door de auteur zelf geschreven?
Hoe verandert ons eigen schrijfgedrag door deze AI patronen? Leuk, een nieuw ✨rabbit home✨ op deze vrije dag. Maar eerst deze teksten afmaken.
Het Pareidolie effect van OpenClaw
Moltbook (of OpenClaw, of hoe het morgen ook heet), Instaclaw (Instagram voor AI Agents) en nu ook Moltmatch (Tinder voor AI Agents). Achter alle agents die daar “zelfstandig” berichten sturen zitten grote LLM-modellen. Het trainingsmateriaal is het internet, waarbij een heel groot deel van de LLM’s is getraind op berichten van Reddit. Het zijn geen entiteiten. Het zijn machines die constant het best mogelijke volgende woord plaatsen en daarbij de illusie wekken dat ze denken en keuzes maken. Terwijl het een computer is die veel rekensommen moet uitvoeren.

We hebben last van Pareidolie, we zien gezichten in wolken, in bomen, huizen en straatmeubilair. We geven onze huisdieren menselijke eigenschappen en we spreken onze computer boos toe als die niet doet wat jij vindt dat die moet doen. Niets menselijks is ons vreemd.
Ik blijf maar denken dat het een setup is voor een enorm grote 1 april grap. Wel een beetje vroeg, dat geef ik toe. De groeiende hysterie is aandoenlijk. AI blijft computerwerk. Geen mensenwerk.
Hoe mijn weken zijn gevuld
Wat heb ik de afgelopen twee weken gedaan dat het hier zo stil is? Ik heb echt wel wat tijd gehad om korte posts te maken, maar het is niet gebeurd. Een schrijfpauze? Nee, ik schrijf nog elke ochtend trouw in mijn Morning Pages. Ik kom bijna tegen de 250 dagen. Elke dag beginnen met een kwartier van me af schrijven. Heerlijk om te doen.
De afgelopen twee weken heb ik hard gewerkt aan een presentatie en workshop voor de eerste betalende opdrachtgever van 2026. Een workshop die ik samen met hun Digital Privacy Officer doe, waar we een groot deel van de medewerkers laten kennis maken met Copilot in hun Microsoft 365 suite. En waarbij we in gaan op het AI beleid van het bedrijf. Wat zijn de afspraken die ze met elkaar maken vanuit veiligheid van data, gebruik van verschillende tools voor werkzaamheden en hoe ze de output van hun AI assistent het beste moeten interpreteren. We geven een aantal sessies in Nederland en België voor de medewerkers. DUs ik ben veel op pad en ik merk dat mijn focus dan veel meer ligt op het werk dan op hier schrijven. Ondanks de AI assistenten om me heen en al die slimme tools, ik kan mijn gedachten het beste op één taak houden. Da’s niet zo gek als mens.  Ik merk het ook als ik met Claude Code en Cowork werk. Ik kan het prima aan het werk zetten om een deel van een project voor me te doen, zoals demomateriaal maken in Word en Excel of mijn brainstorm materiaal verwerken in een plan. Ik denk dat ik ondertussen door kan met andere taken, maar toch blijf ik dat tweede scherm in de gaten houden of alles wel goed gaat. Ik moet soms extra instructies geven, een akkoord geven aan Claude om een lokaal commando uit te voeren. Met als gevolg dat ik mijn eigen taak niet in volle focus kan doen.
We hadden een meetup van de Digitale Fitheid community, waar ik vertelde hoe ik Immich als lokaal fotoarchief gebruik. Van de eerste setup tot het doorlopen van de instellingen. Maar natuurlijk ook de mogelijkheden met gezichtsherkenning en lokaties van foto’s. Weer heel leuk om te doen en naderhand heb ik genoeg gesprekken met communityleden over de details.
Ik merk het ook als ik met Claude Code en Cowork werk. Ik kan het prima aan het werk zetten om een deel van een project voor me te doen, zoals demomateriaal maken in Word en Excel of mijn brainstorm materiaal verwerken in een plan. Ik denk dat ik ondertussen door kan met andere taken, maar toch blijf ik dat tweede scherm in de gaten houden of alles wel goed gaat. Ik moet soms extra instructies geven, een akkoord geven aan Claude om een lokaal commando uit te voeren. Met als gevolg dat ik mijn eigen taak niet in volle focus kan doen.
We hadden een meetup van de Digitale Fitheid community, waar ik vertelde hoe ik Immich als lokaal fotoarchief gebruik. Van de eerste setup tot het doorlopen van de instellingen. Maar natuurlijk ook de mogelijkheden met gezichtsherkenning en lokaties van foto’s. Weer heel leuk om te doen en naderhand heb ik genoeg gesprekken met communityleden over de details.
 Er begint wat tractie te komen op mijn workshops en lezingen. Er zijn genoeg branches en organisaties die echt voelen dat ze iets moeten doen rondom AI. Of minstens iets meer willen weten voor ze keuzes maken. Daar kan ik prima mee helpen. De belangrijkste feedback die ik steeds krijg is mijn nuchtere en menselijke benadering van AI. Het zijn zoemende serverkasten in een datacenter, het heeft geen menselijke eigenschappen. Dat zijn bewuste keuzes die de makers inbouwen in de interface van de programma’s, zodat je er gebruik van blijft maken. Want het voelt zo menselijk. En niets menselijks is mij vreemd, ik val er net zo hard voor. Claude is voor mij nu eenmaal “aardiger” dan ChatGPT. Copilot is een kwispelende labrador die je overal extra hard mee wilt helpen.
Er begint wat tractie te komen op mijn workshops en lezingen. Er zijn genoeg branches en organisaties die echt voelen dat ze iets moeten doen rondom AI. Of minstens iets meer willen weten voor ze keuzes maken. Daar kan ik prima mee helpen. De belangrijkste feedback die ik steeds krijg is mijn nuchtere en menselijke benadering van AI. Het zijn zoemende serverkasten in een datacenter, het heeft geen menselijke eigenschappen. Dat zijn bewuste keuzes die de makers inbouwen in de interface van de programma’s, zodat je er gebruik van blijft maken. Want het voelt zo menselijk. En niets menselijks is mij vreemd, ik val er net zo hard voor. Claude is voor mij nu eenmaal “aardiger” dan ChatGPT. Copilot is een kwispelende labrador die je overal extra hard mee wilt helpen.
We werken met een groep slimme en leuke mensen aan de Pilot Informatie Autonomie, waarin we met verschillende overheidsorganisaties op zoek zijn naar manieren om verder los te breken van het idee dat alle kennis en informatie in documenten hoort. Met documenten bedoelen we dan specifiek Word documenten, die gemaakt zijn voor print en minder geschikt zijn om snel, effectief en vindbaar kennis te verspreiden in je organisatie. Het zijn altijd bijzondere en enerverende dagen, omdat we per sessiedag bekijken wie er zijn van welke organisaties en daar de dag op invullen. Improvisatie, flexibel denken en meebewegen dus.
Tussendoor zijn er veel telefoongesprekken met potentiële opdrachtgevers, mede-onderzoekers, communityleden, potentiële samenwerkingspartners.
Heb ik het té druk? Nee, dat is niet zo. Maar ik blijf wel vaker bewust van mijn laptop af als ik thuis ben en even niets hoef. Dan gaat de TV aan of pak ik een boek.
Maar ondertussen lanceerde ik nog Learn Claude Cowork. Nu nog een landingspagina maar daar komt snel meer informatie over een instapcursus om Claude Cowork te leren in je eigen tijd en tempo.
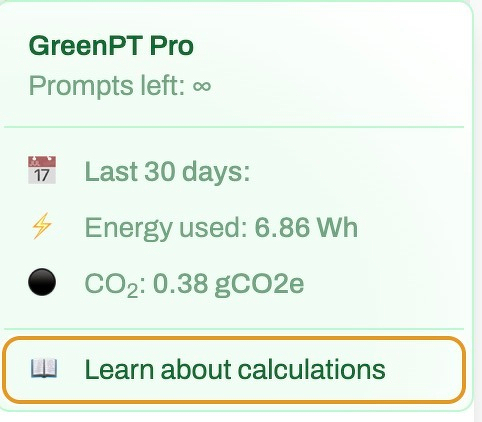
Ik probeerde het lokale GreenPT. Een lokale AI provider met een focus op groene, duurzame en privacyvriendelijke service. Ze houden kantoor in Utrecht en gebruiken Europese datacenters. Ze bieden een standaard chat interface en breiden stap voor stap de mogelijkheden uit. Ze gebruiken lokale modellen waarbij je met elke conversatie inzicht krijg in je CO2 en energieverbruik. Zeker de moeite waard om eens te proberen!
 Komende maandag kun je me zien spreken op de Digitale Fitheid Meetup in Den Bosch, over mijn CreativeNotes project. Volgende week vrijdag geef ik de tweede Claude Code workshop, die inmiddels helemaal vol zit. Tussendoor geef ik nog een AI Geletterdheid workshop aan het onderwijzend personeel van een basisschool, assisteer ik met een AI en Video workshop en ga ik koffie drinken met een ex-collega over een idee voor de aankomende PKM Summit. Mooie dagen voor de boeg!
Komende maandag kun je me zien spreken op de Digitale Fitheid Meetup in Den Bosch, over mijn CreativeNotes project. Volgende week vrijdag geef ik de tweede Claude Code workshop, die inmiddels helemaal vol zit. Tussendoor geef ik nog een AI Geletterdheid workshop aan het onderwijzend personeel van een basisschool, assisteer ik met een AI en Video workshop en ga ik koffie drinken met een ex-collega over een idee voor de aankomende PKM Summit. Mooie dagen voor de boeg!
Winter Garden, de popup nieuwsbrief over AI.

Ik heb al vaker over Robin Sloan geschreven. Hij is van mijn favoriete fictie-schrijvers omdat hij technologie en creativiteit op een beeldende manier combineert. Niet alleen in zijn boeken zoals Mr. Penumbra’s 24 hour bookstore, Sourdough en zijn laatste roman Moonbound. Ik koop trouw zijn posters, vermomd als zines. Sloan is continu zelf bezig met technologie. Al in 2016 experimenteerde hij met een eigen ontwikkeld taalmodel.
Vanwege het jubileum van dit model start hij een pop-up nieuwsbrief. Een gratis nieuwsbrief die slechts zes edities zal bestaan en dan verdwijnt. Het onderwerp is AI, vanuit het perspectief van een schrijver en programmeur die sinds 2016 met deze technologieën werkt. De titel is Winter Garden, de eerste editie is er en ik ben er dol op. Hij legt in de eerste editie uit waarom we nu al te maken hebben met AGI, Artificial General Intelligence. Vooral als je terugblikt op de afgelopen jaren en de evolutie van de grote modellen.
It’s important to emphasize that the capability of these big models was a genuine surprise, even to their custodians. Once understood, the opportunity was quickly grasped … but the magnitude of that initial whoa ?! is still ringing the bell of this century.
Maar hij stelt tegelijk de belangrijkste vraag… Wat nu?
Abonneert allen!
Doorzoek je Claude Code gesprekken
Dit is precies wat ik bedoel met digitale democratisering, of perfecte software voor een publiek van één volgens Gaurav Ramesh (dank Erwin!)
Simon Willison lost een probleem voor zichzelf op, hoe kan ik beter door de transcripts van Claude Code zoeken en navigeren, en deelt dat met de rest van het internet. Hij heeft net als ik het probleem dat je zoveel doet in Claude en Claude Code, dat zoeken ín de chatsessies belangrijk is. Om te achterhalen wat je precies had gedaan, welke opdracht waar is gegeven of waarom bepaalde keuzes zijn gemaakt.
Zijn Claude Code Transcripts tool is een elegante oplossing, je kiest een chatsessie uit je geschiedenis en je krijgt direct een HTML pagina met de volledige tekst, inclusief de denk-stappen van het model. In de README file van de tool geeft Willison nog meer commando’s en output opties.
De reden om deze tool te maken vind ik minstens zo opmerkelijk:
These days I’m writing significantly more code via Claude Code than by typing text into a text editor myself. I’m actually getting more coding work done on my phone than on my laptop, thanks to the Claude Code interface in Anthropic’s Claude iPhone app. Being able to have an idea on a walk and turn that into working, tested and documented code from a couple of prompts on my phone is a truly science fiction way of working. I’m enjoying it a lot.
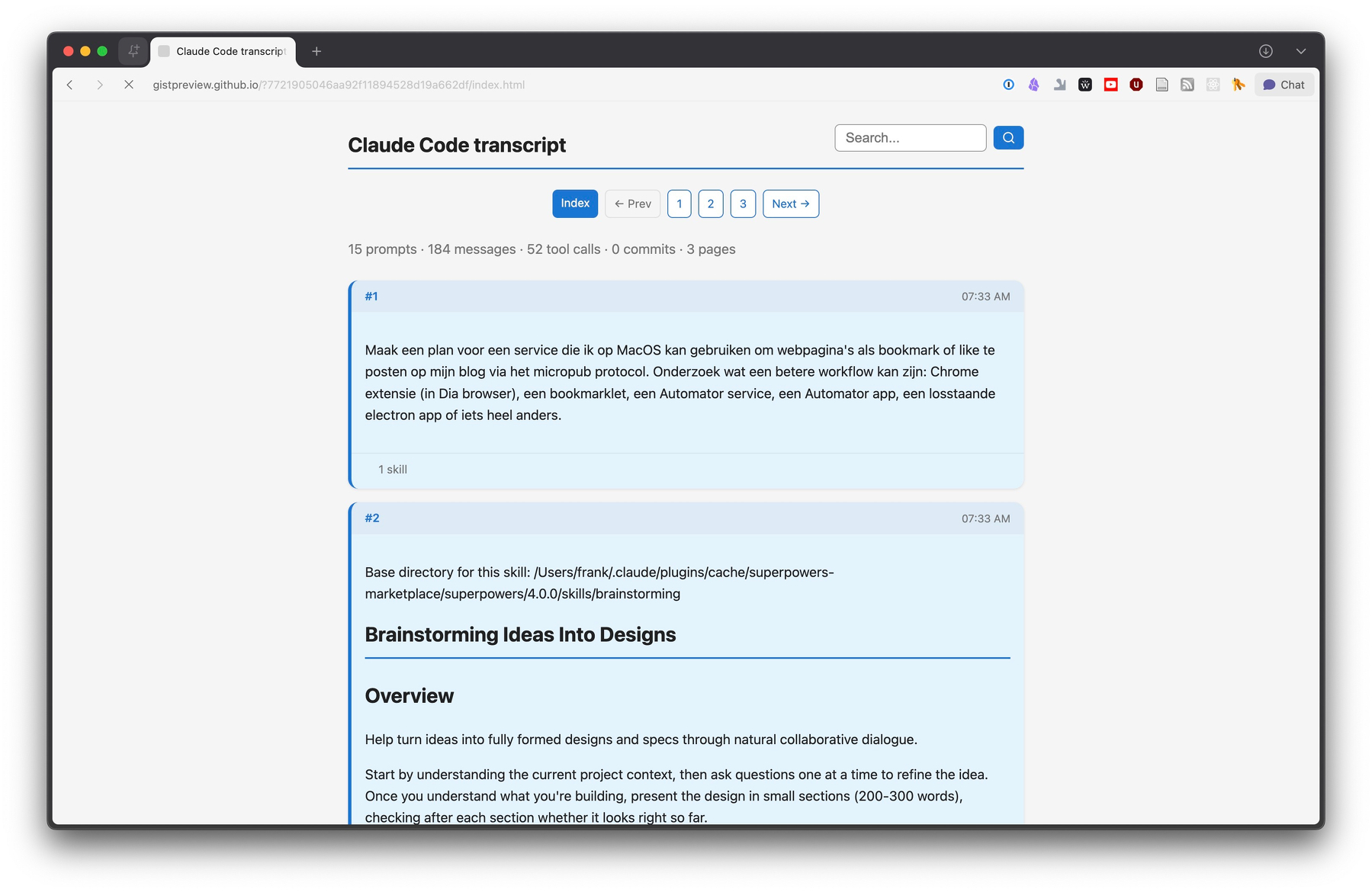
En het werkt best aardig! Zie hier een transcript van een sessie waar ik nu mee bezig ben, om een nieuwe bookmark/like extensie te maken die werkt zoals ik het liefste heb.
Mooi spul! Claude Code Transcripts
Hoe AI-tools de derde golf van digitale democratisering inluiden
We staan aan de vooravond van een nieuwe technologische golf. Zo. Ik heb gesproken.
AI-tools maken het nu al mogelijk om zonder programmeerkennis eigen persoonlijke software te bouwen. We zijn nog niet in het stadium dat er productieklare, schaalbare apps ontstaan. Maar een app die direct een probleem oplost voor een individuele gebruiker? Of die iets mogelijk maakt wat voorheen niet kon? Daar staan we nu.
Het roept vragen op die we eerder moesten stellen. Wat betekent het als miljoenen mensen hun eigen apps kunnen maken? Wie bouwt de infrastructuur om deze veilig te delen? Hoe voorkomen we dat dit nieuwe ecosysteem wordt opgeslokt door dezelfde platforms die het open web hebben opgeslokt de afgelopen 15 jaar? En hoe zit het met de schaduwkanten van AI: de privacy-implicaties, het dataverbruik voor training, de ethische dilemma’s, het gebrek aan diversiteit in de trainingsdata, de milieubelasting van datacenters, de kosten die niet voor iedereen gelijk zijn?
Die vragen beheersen nu het gesprek en dat is logisch. Want als we iets hebben geleerd van de afgelopen twintig jaar BigTech, dan is het dat ze de regels schrijven tijdens de verspreiding van technologie. Dus is het goed dat al die vragen er nu zijn. Tegelijk bekijken we waar de kansen liggen.
Think Different
Afgelopen vrijdag 19 december liet Martijn zien wat hij kon maken zonder enige programmeerkennis. Zijn ThetaOS spreekt tot de verbeelding, maar nog belangrijker dan de app zijn de checks and balances die hij onder water bouwt en beheert. Hier publiceert hij veel over en we hebben er geregeld gesprekken over. We steken elkaar aan met ideeën, helpen elkaar vooruit met inzichten en ik kijk graag over zijn schouder mee wat hij doet. 
Zijn verhaal paste perfect bij de workshop van die ochtend. Voor een groep van 25 enthousiaste niet-programmeurs ging een wereld open met Claude Code. Hier zag ik met eigen ogen de technische barrière instorten die decennia standhield. Martijn schrijft over de scheur in de muur van de App Stores, ik zag hem ontstaan in dat zaaltje.
In 2 uur zag ik een persoonlijke wijndatabase verschijnen, een privé mobiele klantenkaart app die geen data slurpt, een app om je tuin op orde te houden door het jaar heen, een Zweedse taal app, een Spaanse taal app (want beiden hebben een hekel aan de enshittification van Duolingo), de opzet naar een eigen takenmanager, een comicstrip creator. Ik zag de rest van de dag een andere deelnemer constant bedenken wat ze nu allemaal kon maken. Welke Final Boss krachten nu unlocked waren… En een dag later kreeg ik een bericht dat een andere deelnemer zijn persoonlijke CRM systeem nu op orde had.
“Ik ben bloody blown away met wat allemaal mogelijk is”, is slechts één van de reviews die ik via mail, Signal en in gesprekken kreeg.
30 januari kun je het zelf ervaren als ik de workshop nog een keer geef. Natuurlijk kun je me altijd mailen of DM’en voor een in-company startersessie Conversational-Driven Development.
Drie golven van democratisering
Hoe chaotisch het web kan zijn: haar geschiedenis kent een patroon. Telkens wanneer een technische drempel valt, ontstaat een explosie van creativiteit van onderop.
De eerste golf: publicatie (1999-2005)
Begin 1999 waren er 23 bekende weblogs. Rebecca Blood, pionier en historicus van de blogcultuur, documenteerde wat er toen gebeurde. De belofte van het web was dat iedereen kon publiceren. De werkelijkheid was anders: alleen mensen die HTML beheersten konden hun stem laten horen. Toen lanceerden o.a. Pitas en Blogger. Plotseling konden mensen zonder technische kennis een eigen plek op het web claimen. Ik kan het weten, ik was erbij. Ik heb er zelfs nog een boek over geschreven. Binnen een paar maanden waren er honderden blogs. Binnen een paar jaar miljoenen. En zo ontstond een hele cultuur: de blogosphere, met eigen zoekmachines (Technorati), eigen conventies voor exploratie en ontdekking (trackbacks, blogrolls), eigen sterren en schandalen. En vooruit, eigen awards…
Het belangrijkste was dat de technologie om iets te publiceren op het web ineens voor iedereen beschikbaar was. Naast blogs kregen ook persoonlijke webpagina’s een enorme boost, met hun eigen beeldtaal, los van wat we kenden van magazines, TV en kranten.
De tweede golf: netwerk (2005-2012)
Je blog was een uitzendmedium. Jesse James Garrett noemde ze de Pirate Radio Stations of the web. Het zijn persoonlijke platformen waar je als individu je mening kunt geven. Je publiceerde, hopend dat iemand het zou vinden. Social media draaide dit om: het netwerk kwam eerst. Facebook, Twitter, en in Nederland Hyves maakten zichzelf de kern van de verbindingen. Je hoefde niet eens te publiceren om deel te nemen. Als blogger waren we nog producent. De sociale kanalen maakten weer consumenten van ons. Ondanks de kleine interacties van likes, shares en comments, écht iets maken was er nog maar weinig bij. Het werd nog erger. Algoritmes optimaliseerden op engagement, die veelal op woede en polarisatie is gericht, de aandacht op het platform werd verkocht aan de hoogste bieder en onze data wordt gebruikt om ons constant te tracken. En om nu LLM’s mee te voeden. Wat me op de derde golf brengt.
De derde golf: creatie (2008-nu)
Parallel aan de opkomst van social media begon een andere revolutie. De iPhone lanceerde in 2007, de App Store opende in 2008. Plotseling kon software op een apparaat in je broekzak draaien. Maar de technische drempel bleef hoog en Apple voegde daar nog een laag aan toe: Elke app kende een review-proces en een commissie van 30% op elke transactie. Martijn beschrijft in zijn stuk uitgebreid hoe we door AI code-assistenten die technische muur laten instorten. Met Claude Code maak je je eigen applicaties. Dat kunnen webapplicaties zijn, of volwaardige iPhone apps. Android zal net zo goed mogelijk zijn, maar valt buiten mijn kennis van dat ecosysteem. Martijn, ikzelf, deelnemers aan de workshops en Digitale Fitheid Meetups, we beschrijven wat we willen en samen met de software werken we naar een eindresultaat. En zo ontstaan er miljoenen niche-apps, gedeeld buiten de App Store. Die zijn niet bedoeld voor massamarkten, maar voor persoonlijk en wellicht klein-gemeenschappelijk gebruik.
| Golf | Periode | Barrière die viel | Wat het mogelijk maakte | Wat ontstond |
|---|---|---|---|---|
| Publicatie | 1999-2005 | HTML-kennis | Blogger, WordPress | Blogosphere |
| Netwerk | 2005-2012 | Bereik, verbinding | Facebook, Twitter, Hyves | Social web |
| Creatie | 2008-nu | Programmeerkennis | App Store → AI-tools | ? |
Het vraagteken in die laatste cel maakt het interessant. Wat zal onstaan?
Wat we verloren
Om te begrijpen wat er kan ontstaan, moeten we eerst begrijpen wat we kwijtraakten.
In december 2012 schreef technologie-commentator Anil Dash een essay dat nog steeds nagalmt: “The Web We Lost.” Hij beschreef hoe de tech-industrie de opkomst van netwerken behandelde als pure winst voor gebruikers. Zelden werd gesproken over wat we onderweg eigenlijk verloren. Dash herinnerde zich een web waar foto’s op Flickr werden geüpload met tags die machines én mensen konden lezen. Waar je met Technorati de blogosphere in real-time kon doorzoeken. Waar sites naar elkaar linkten en die links meer betekenis hadden dan om SEO redenen. Afgelopen vrijdag hadden Ton Zijlstra en ik een nostalgisch gesprek over del.icio.us, de beste sociale bookmarktool die nooit tot volle wasdom kon komen. Maar waar je elkaar volgde op basis van de linkverzameling en tags.
Maar het echte verlies was subtieler: de persoonlijke homepage. In de jaren negentig had je een homepage. Een digitale plek die jou representeerde, vormgegeven naar jouw smaak, met jouw inhoud, onder jouw controle. Het was rommelig en amateuristisch en prachtig. Elke homepage was anders, want elke maker was anders. Sociale platforms reduceerden dit tot een profiel. Dezelfde MySpace, Facebook, Hyves of Twitter template voor iedereen. Dezelfde mogelijkheden, dezelfde beperkingen. Onze identiteit werd een invulformulier. Nog zonder captcha om verkeerslichten en pinguins te herkennen.
De terugkeer
Wat Martijn beschrijft is niet zomaar een technische ontwikkeling. Hij ziet dat zelf ook. Het is de mogelijke terugkeer van iets dat we verloren waanden, maar met een cruciale upgrade. Een homepage was statisch. Een blog was chronologisch. Een app is functioneel. AI-gegenereerde apps zijn “persoonlijke homepages” die iets doen. Ze lossen een probleem op dat jij hebt. Ze werken op de manier die jij prettig vindt. Ze delen geen data met adverteerders. Ze worden niet slechter omdat een platform besluit meer geld te verdienen.
Martijn voorspelt miljoenen niche-apps, gedeeld buiten de App Store. Dit is precies wat Harvard-professor Yochai Benkler in 2006 beschreef als “commons-based peer production”: gedecentraliseerd, collaborative, niet gericht op eigendom of winst. Het verschil met twintig jaar geleden: de tools bestonden nog niet om dit werkelijk op grote schaal te realiseren. Nu wel.
Waarom eigenaarschap ertoe doet
De academische literatuur over online platforms is de afgelopen twintig jaar geëxplodeerd. De conclusies zijn ontnuchterend en dat zal je niets verbazen. Mensen als Shoshana Zuboff(Surveillance Capitalism), Nick Srnicek(Platform Capitalism) en Cory Doctorow (Enshittification) maken duidelijk dat het social web er niet lekker aan toe is. Het werkt alleen bij afhankelijkheid van het platform. Een zelfgebouwde app is minder afhankelijk. De afhankelijkheid is er tot op zekere hoogte, want het is met AI gebouwd. Maar je zit meer aan de knoppen wat je idee moet doen en kunnen. En vooral wat het niet moet doen. Geen algehele platformbeslissingen. Geen advertenties. Geen API-toegang die plotseling wordt afgesloten. Geen 30% commissie. Geen willekeurige afwijzing door reviewers.
De IndieWeb-les
Ik was betrokken bij de IndieWeb-beweging in Nederland en ervaar constant wat het effect kan zijn als je echt autonoom bent. Als alles in je eigen bezit is. Het geeft een digitale vrijheid die moeilijk te beschrijven is.
Technologie alleen is echter niet genoeg. De University of Toronto concludeerde in hun onderzoek naar het Indieweb: “Voor een beweging die individuele autonomie benadrukt, zijn IndieWeb’s evenementen en community-netwerken de drijvende kracht achter haar levensduur.”
De blogosphere stortte niet in door technische beperkingen. Technorati indexeerde 133 miljoen blogs. Maar 94% verdween. Niet omdat bloggen ineens moeilijker werd, maar omdat de sociale infrastructuur verschoof naar platforms die engagement optimaliseerden boven betekenis.
Wat ik me dus afvraag…
Als de AI-codetools werkelijk een nieuwe fase van digitale democratisering inluiden, dan staan we voor vragen die we eerder hadden moeten stellen. De vragen die we vergaten bij de komst van blogs en sociale netwerken.
Wat is het RSS-protocol voor apps? RSS maakte het mogelijk om blogs te volgen zonder een platform als tussenpersoon. Wat is het equivalent voor niche-apps? Hoe vind je de app die iemand in Australië bouwde voor precies jouw probleem? Wie bouwt de Technorati voor AI-gegenereerde software? Misschien ligt een deel van het antwoord in protocollen zoals Nostr: open standaarden die discovery en connectie mogelijk maken zonder een centrale poortwachter.
Wat voorkomt dat dit ook enshittified? Platforms slokten de blogosphere op. Influencers en social creators zijn afhankelijk van ondoorgrondelijke algoritmes. Welke structuren voorkomen dat deze app-renaissance hetzelfde lot ondergaat?
Wie bouwt de commons? Martijn voorspelt platforms voor het delen van broncode, “GitHub meets App Store.” Maar wie bouwt dit? En volgens welk model? Is het eigendom van de community of van het platform?
Hoe gaan we om met de schaduwkanten? AI-tools zijn niet neutraal. Ze zijn getraind op data waarvan de herkomst niet altijd helder is. Ze draaien op datacenters die te veel water en energie verbruiken. Ze kosten geld dat niet voor iedereen gelijk beschikbaar is. Ze roepen vragen op over privacy, over eigenaarschap van gegenereerde code, over de arbeidsomstandigheden van mensen die trainingsdata labelen. We kunnen niet doen alsof deze vragen niet bestaan. De vraag is hoe we een dialoog voeren die zowel de mogelijkheden erkent als de kosten eerlijk weegt.
Wat is de nieuwe digitale geletterdheid? Als software-creatie een basale vaardigheid wordt, wat betekent dit dan voor onderwijs? Voor werk? Voor de definitie van wat het betekent om digitaal vaardig te zijn?
En de belangrijkste vraag: De homepage verdween niet omdat hij technisch onmogelijk werd. Hij verdween omdat platforms makkelijker waren en meer bereik boden. De technische barrière voor apps is nu weg. Maar de sociale en economische krachten die ons naar platforms duwden bestaan nog steeds. Wat is er dit keer anders?
Een open einde
Misschien is het antwoord: niets is anders. Misschien worden AI-gegenereerde apps een nieuwe categorie die de grote platforms zullen absorberen en monetizen. Want dat is nu eenmaal zoals de BigTech werkt: Embrace, extend en extinguish.
Maar ik blijf die naïeve hoop houden. Misschien is er wel iets veranderd. Want we moeten toch íets hebben geleerd van de afgelopen twintig jaar aan Big Tech platform dominantie? We weten nu wat we verliezen als we bouwen op geleend land, zoals Twitter. We ondervinden de enshittification aan den lijve. We zien hoe ze onze data opslurpen, verzamelen, bundelen en verkopen aan bedrijven en overheden. Hoe ze onze digitale identiteit reduceren tot een profiel in andermans template.
Toen we in 2000 lekker zaten te bloggen, wisten we niet wat we hadden. Tot het weg was. Nu weten we wel beter. Toch? De vraag is of die kennis genoeg is om het dit keer anders te doen. En of we bereid zijn om de moeilijke gesprekken te voeren over hoe we nieuwe technologie inzetten op een manier die individuele makers helpt, zonder de wereld naar de knoppen te helpen.
Nieuwsgierig?
Leuk, dat historisch perspectief, maar wat nu? Wel, je kunt er onderdeel van uitmaken. Het zelf meemaken! 30 januari geef ik de Claude Code Open workshop nog een keer. Gratis en voor niks bij Wonders of Work in Utrecht. Wil je met je team of bedrijf proeven aan deze nieuwe revolutie? Dan is een in-company workshop altijd mogelijk. Mail me!
Mijn Claude Code AI app is heus geen zoemende server in Silicon Valley! Het zit echt ergens in een kantoor mijn code te debuggen. Of in elk geval, dat probeert het. Want het maakte zelf een domme fout. Toen ik er naar vroeg kreeg ik uitgebreide excuses. Waaronder:
Het echte probleem zat tussen stoel en toetsenbord - ik blokkeerde de server met mijn eigen test commands. Een maand geleden werkte alles omdat je toen geen debug commands had draaien.
Zou dat nou die Soul zijn bij Anthropic waar zoveel om te doen is?
Ik moet soms echt wel een beetje lachen om Claude. Ondanks dat het een Algoritmisch Inschattingsmodel is!
Agents en skills
Ik zat begin deze middag met een probleem. Ik wilde Claude Code een agent laten maken die ISO tests (dank je wel Monique) op mijn code kon doen. Zelfstandig, zonder mij te veel lastig te vallen. En natuurlijk met feedback. Maar wat Claude Code gaf was een skill, maar dat was volgens mij niet wat ik nodig had.
Dat bracht me op het agents versus skills concept wat ik nog steeds niet goed begrijp en volgens mij andere mensen ook niet: agents en skills zien er misschien op het oppervlak hetzelfde uit (allebei mappen met instructies), maar ze zijn totaal anders. Of eigenlijk liggen ze heel dicht bij elkaar in mijn hoofd. Een agent heeft bepaalde skills. Een tekstschrijver kan zelfstandig teksten schrijven en heeft de competenties om dat te doen. Maar waarom zijn die twee dan gescheiden? Het blijkt dus, het gaat niet zozeer om techniek als om je rol:
En de keuze bepaalt eigenlijk hoe je Claude Code gaat inzetten.
Een handleiding versus een collega
Skills zijn instructiehandboeken. Agents zijn zelfstandige specialisten.
Een Skill zit in een mapje met een SKILL.md bestand met richtlijnen, voorbeelden en referentiematerialen. Wanneer jij Claude iets vraagt, scant hij of een Skill relevant is. Zo ja, dan laadt hij ze in. Hij leest de instructies en volgt ze op. Ik wacht er ondertussen op totdat Claude klaar is.
Een Agent is anders. Het zijn Mini-Claude’s met hun eigen system prompt, toolset en afzonderlijke context window van 200.000 tokens. Agents zijn eigenlijk een team van experts: ze hebben elk hun eigen rol en functie. Ze gaan zelfstandig aan de slag, kunnen fouten herkennen, teruggaan, opnieuw proberen en itereren. Ze rapporteren terug met resultaten, niet met “ik ben klaar met je instructies volgen”.
Praktisch gesteld:
Een Skill zegt: “Hier staan de richtlijnen voor branding, volg ze netjes.”
Een Agent zegt: “Jij bent de design expert. Ga zelfstandig controleren of deze site aan onze brand guidelines voldoet. Rapporteer terug wat er mis is en wat je zou aanpassen.”
Waar het ingewikkelder wordt in mijn hoofd
Dit is het kernverschil. Maar nu wordt het interessant, want ik moet een keuze maken. En die keuze bepaalt eigenlijk hoe het werk gaat verlopen.
Ik merkte dat op het moment dat ik Claude Code vraag om bijvoorbeeld: “Controleer mijn code op performance issues.” Claude Code kan kiezen: Skill of Agent?
Als Claude een Skill maakt, laadt die in mijn huidige window. Claude leest de performance-checklist, volgt stap voor stap wat ik heb geschreven en geeft feedback. Het is snel, synchroon, en ik ben niet afhankelijk van agents die hun eigen gang gaan.
Als Claude een Agent maakt, maak ik eigenlijk een specialist aan die onafhankelijk werkt. Die Agent gaat mijn code analyseren, kan teruggaan en dieper graven, kan voorstellen testen, kan itereren. Ik hoef niet te wachten. Ik laat de Agent los en ga zelf verder met iets anders. De Agent rapporteert later.
Delegeren of dirigeren
Hier zit de echte beslissing. Het gaat niet zozeer om de techniek als om de werkwijze die ik prettig vind met AI-modellen. En dat is iets waar ik ook nog steeds aan moet wennen: wanneer wil ik nou eigenlijk een agent gebruiken en wanneer wil ik een skill gebruiken? Ik weet dat nog steeds niet heel goed. Maar langzaam zie ik wel een patroon.
Agents zijn voor exploratie en verbetering. Je zet ze in als je:
Praktisch voorbeeld: ik heb een codebase met 50 bestanden en ik wil dat Claude die doorloopt, security issues vindt, patches voorstelt en die test. Ik kies dan voor een agent, want die gaat zelfstandig aan de slag. Ik kan ondertussen iets anders doen.
Skills zijn voor regels en standaarden. Je zet ze in als je:
Praktisch voorbeeld: ik heb brand guidelines geschreven en ik wil dat Claude die altijd toepast bij documenten. Ik kies dan voor een skill. Claude leert het, past het toe als het nodig is.

De fout die ik bijna maakte
Dus ik wilde een ISO-test agent. Claude Code maakte een Skill. Ik zat even te denken: kan ik niet gewoon een Agent maken die die ISO-Skill inlaadt?
Een agent die een Skill inlaadt is dubbel werk. Je agent zou in feite zeggen: “Wacht, laat me eerst deze handleiding lezen” en dan de instructies volgen. Dat kost dus extra tokens voor iets wat eigenlijk niet nodig is. Dan kan ik net zo goed zelf dat handboek lezen en het werk zelf doen. “Laat maar, ik doe het zelf wel” - en dan ben je sneller klaar.
Waar ze wel samenwerken
Nou, er is één scenario waar het wel voordelig is. Niet voor dezelfde taak, maar complementair.
Stel je de Ticket-beheerder agent voor. Die Agent doet iets groots: aanvragen verwerken, prioriteiten stellen, bepalen wie het gaat oppakken. En incidenteel heeft die Agent iets nodig wat in een Skill staat. Bijvoorbeeld: “Zorg ervoor dat alle output aan onze schrijfstijl voldoet.”
Dan kan de Ticket-beheerder agent die Schrijfstijl-Skill inladen wanneer nodig. Dat is niet dubbel werk, dat is praktisch. De Agent delegeert een onderdeel van zijn taak naar gespecialiseerde instructies.
Dit illustreert eigenlijk een belangrijke nuance: Skills zijn voor “volg de regels” - je wilt consistency en standaarden. Agents zijn voor “maak het beter” - je wilt dat iemand nadenkt, itereert, verbetert. De Ticket-beheerder hoeft niet na te denken over schrijfstijl (daar zijn regels voor), maar wel over wat de beste aanpak is om tickets op te lossen.
De mindset shift
Ik dacht eerst, Claude Code is een assistent die me helpt. Ik zit aan het stuur en Claude voert uit.
Maar met agents gebeurt er iets anders. Je gaat delegeren. Je zet specialisten in. Je hebt minder controle per moment, maar je hebt meer output totaal. Omdat agents parallel kunnen werken. Omdat ze zelfstandig kunnen itereren. Omdat ze context ruimte hebben om écht diep te gaan.
Skills passen in het “Claude helpt me” model. Je bent stuurman. Claude is copiloot.
Agents passen in het “ik delegeer werk” model. Je bent projectleider. Claude je team.
En gaandeweg ontdekte ik nog iets: je kunt deze twee ook combineren in je workflow. Je zet Agents in voor de exploratie en verbetering. Laat ze het werk beter maken, dieper graven. En als je tevreden bent met het resultaat, vertaal je die kennis naar Skills. Die worden dan de regels en standaarden die je altijd wilt toepassen. Agents voor de vraag “hoe maken we dit beter?”, Skills voor de regel “dit doen we altijd zo”.
De volgende stap
Ik ga mijn ISO-test Skill omzetten naar een Agent. Niet omdat het technisch beter is, maar omdat ik wil dat die zelfstandig code doorloopt, fouten markeert, voorstellen test en rapporteert. Ik wil delegeren. Ik wil dat die specialist eigenaarschap neemt.
Dus: heb je werk dat complex is? Dat iteratie nodig heeft? Dat je parallel wilt doen? Maak een Agent.
Heb je werk dat consistent moet en deel van je standaardproces? Maak een Skill.
De keuze bepaalt eigenlijk hoe je Claude Code gaat ervaren. Of je Claude als assistent voelt, of als team.
Ik zit nu bij de Digitale Fitheid meetup. We hebben het vooral over zelf apps maken met behulp van AI. Of dat nu een eigen dashboard is, een static site exporteren of een eigen cursus Zweeds. Mooi dit. Van “There’s an app for that” naar “There’s a prompt for that”
Opgeslagen ideeën
Als Elja het over Vervlogen Ideeën heeft, wie ben ik dan om achter te blijven met wat eigen observaties. En wat er zoal de afgelopen tijd gebeurt. Ik was ook uitgenodigd voor de boekpresentatie waar Elja was. De auteur is een vriend van me, we hebben samengewerkt op de Hogeschool Utrecht, zo’n 15 jaar geleden. Ik kan goede gesprekken met hem voeren over AI. De voors en tegens. De gevaren en de mogelijkheden. Laurens houdt me scherp op wat de andere kant is van al deze ontwikkelingen.
Vanochtend sprak ik Marieke. Ze is de host van de Digitale Fitheid meetups in Den Bosch. In januari is de volgende editie, komt allen! Er schijnt een spreker te zijn die iets vertelt over analoge notities en creativiteit… 😏 Marieke en ik hebben een dik uur wat bij zitten praten over de lastige (onmogelijke?) belofte dat AI je productiviteit verhoogt. Vanuit praktisch perspectief, vanuit wetenschappelijk perspectief. Ik vind dat soort gesprekken heerlijk.
Morgen is trouwens de maandelijkse Digitale Fitheid meetup in Utrecht. Kun je me ook in het wild tegenkomen.
Afgelopen week is de eerste offerte de deur uit voor een serie AI Workshops in 2026. De eerste offerte als nieuwe ondernemer. Een momentje hoor. De eerste factuur mocht ook de deur uit. Daar hoefde ik niet eens een offerte voor te sturen. Nog mooier!
En het boekvoorstel voor CreativeNotes is eindelijk af! Ik zat er enorm tegen te hikken om het te schrijven. Ik kreeg geen orde en organisatie in mijn teksten, in de interviews, de hoofdstuk-indeling, losse gedachten en flarden quotes. Dat zorgt bij mij voor uitstelgedrag en in mijn hoofd ga ik rondjes draaien met gedachten om het probleem op te lossen. In plaats van aan mijn bureau te gaan zitten en het op te lossen. Dat moest gebeuren.
Samen schrijven
Uiteindelijk heb ik in Claude Code een hele strikte schrijfcoach-agent gemaakt. Die kon orde brengen in alles wat ik al had liggen. Stelde me kritische vragen over de indeling van het boek. Ging soms iets te ver en bleef maar op één onderwerp doorduwen. Dus dan grijp ik in. Ik pas de agent aan en we gaan weer verder. De agent genaamd Noah (geen idee, de naam popte in mijn hoofd), kon me vervolgens uitstekend helpen met de opbouw en inrichting van het boekvoorstel. Het mooie aan Claude Code is dat het direct bestanden op mijn laptop maakt. Binnen de grenzen van een subdirectory natuurlijk. Met allerlei vangrails en allow/deny toestemmingen bewust ingesteld.
Claude Code en Noah maken Markdown bestanden voor me, die ik direct in Obsidian kan bekijken, wijzigen en opmerkingen in kan maken. Zo maak ik samen een boekvoorstel, waar ik alle zinnen en woorden altijd zelf bekijk en beoordeel. Waar ik me afvraag, zou ik het zo schrijven? Het mooie is dat Claude Code eveneens een schrijfgids heeft met mijn schrijfstijl. Die is opgebouwd uit een flink aantal blogposts en artikelen. Daarmee geef ik het wederom richting hoe het voor mij werk kan doen.
Keuzes
Dit is allemaal een logisch vervolg op de eerdere experimenten om een boek te structureren. Want ik gebruik nu nog meer voice-to-text om mijn ideeën en opdrachten over te brengen. Niet meer met Wispr Flow maar met de open source app Hex (sorry, Mac only). De open source modellen van Parakeet en Whisper zijn zo goed dat ik vrij foutloze teksten kan inspreken. Zo praat ik tegen mijn computer, geef ik opdrachten, denk ik na over de richting van een hoofdstuk.
Mijn doel is om zo goed mogelijk richting te geven aan AI om het werk te doen wat ik wil dat het doe. Met name de klusjes die prima zijn te automatiseren. Na elke sessie schrijft een andere agent een verslag wat we hebben gedaan, welke taken nog open staan en het zorgt dat alle gewijzigde bestanden netjes worden gesynchroniseerd met een self-hosted git server. Ik zorg dat al mijn ideeën worden opgeslagen. Of ik doe het zelf op papier en digitaal. Of ik zeg mijn computer dat die het moet doen.
Ik vraag me af hoe deze manier van werken zich verhoudt tot de ideeën die in boek Niet Onze AI presenteert. Mijn exemplaar kwam vandaag binnen, dus ik ga het eens lezen. Gewoon op papier. Met indexkaarten om aantekeningen te maken. Om de ideeën op te slaan die ik tegenkom.
Nieuw commentsysteem
Ik denk dat het allemaal is gelukt.
(Voice-over: Update, het is dus niet gelukt… het oude systeem staat voorlopig weer terug)
Het reactiesysteem voor mijn blog had ik extern gehost bij de maker, Cusdis. En dat ging langzaam maar zeker stuk. Zo kreeg ik geen email notificaties meer als er nieuwe reacties waren. En moesten sowieso alle reacties worden goedgekeurd. Nu blijkt dat de maker zijn systeem heeft achtergelaten en te koop heeft staan Een hoop gedoe. Gelukkig kan ik het reactiesysteem ook zelf hosten. Die knop is nu omgezet. Als het goed is zie je nog altijd een reactieveld hieronder. Kun je een reactie achterlaten. En moet ik die nog wel goedkeuren. Er zijn nog een paar hobbels die ik komende dagen moet nemen:
Met name de derde hobbel is nog een interessante. De hosted versie van Cusdis biedt geen mogelijkheid om je reacties te exporteren. Daar had ik beter op moeten letten toen ik er mee begon, maar dat is nu wat het is. Gelukkig kan ik met wat handigheid in de Developer tools van de browser wel alle ruwe data van de reacties ophalen. Ik wil nog uitvogelen of ik dat met een AI-powered brokje code kan automatiseren (vast, maar ik weet nog niet hoe) en weer kan importeren in mijn bestaande systeem. Dan zijn de reacties sowieso weer terug.
Genoeg nieuw gedoe dus. Maar het is gedoe in eigen beheer. Dat voelt toch fijner.
Laat gerust een reactie achter om te testen hoe alles werkt :-)
Hoe we van de WYSIWYG-leugen naar echte samenwerking gaan
Toen ik Wilfred’s artikel las over docenten die hun eigen educatieve apps maken, moest ik denken aan mijn tijd bij Kaliber. We maakten daar zelf tools om onze klanten beter te helpen in werkprocessen. Die maakten we zelf met low-code apps als Make.com en werden zelden door developers gebouwd. Die driedeling die Wilfred beschrijft (voordelen en nadelen voor lerenden, docenten, en organisaties) komt me bekend voor. Vooral omdat ik inmiddels weet dat al die voor- en nadelen eigenlijk prima op te lossen zijn door samen te werken.
Maar daar zit ook meteen een uitdaging.
De cyclus die maar doorgaat
We gebruikten Make.com, Typeform, en steeds vaker AI-tools zoals Claude om die klanttools te bouwen. Het enthousiasme was groot. Net zoals bij die docenten met hun AI-apps nu. Maar wat me opviel: het duurt heel lang voordat je echt een goed werkende versie hebt. Je kunt op papier veel uitdenken, maar je moet echt samenwerken met elkaar om tot een uitgewerkte tool te komen. Het is niet iets wat je even op een avondje maakt en dan de wereld inslingert.
En hier zit het patroon dat me fascineert. Want de belofte dat je het allemaal zelf kunt maken, die is niet nieuw.

In de jaren ‘90 hadden we WYSIWYG editors zoals Dreamweaver en Frontpage die het handmatig HTML-werk in bv Hotdog Editor eenvoudiger zou maken. We kregen blogging tools zoals Blogger, Movable Type en WordPress: je maakt je site in de browser met templates! Daarna kwamen no-code en low-code tooling: nu kun je echt alles zelf maken! En nu AI tools met dezelfde belofte: eindelijk kun je het allemaal zelf.
Een observatie over die cyclus van developer-tools: Altijd werd gezegd dat programmeurs overbodig worden, dat je als non-developer het allemaal zelf kunt. Dat bleek dan toch aardig flauwekul. Je kunt een hoop zelf, maar wil je echt kwalitatief goed en stevig werk, dan heb je experts nodig.
Je zult moeten samenwerken. Want als je alles door AI laat doen, wordt alles hetzelfde, ziet het er hetzelfde uit, het zit niet in je eigen stijl, het heeft niet je eigen tone of voice. Daarvoor heb je echt andere expertise nodig. Van UX tot design, development en niet te vergeten mensen met verstand van zaken om de boel op een productieserver te zetten en te houden.
Samen groeien
Wilfred analyseert scherp vanuit die drie perspectieven, waarin hij uitgaat van de individuele docent die zelf de apps ontwikkelt. Ik denk dat dit juist het moment is om je organisatie erin mee te krijgen en het gezamenlijk te gaan doen.
Want kijk wat er gebeurt als je die samenwerking wel organiseert: Je brengt alle juiste expertises bij elkaar, van learning analytics, leerdoelen, beveiliging en integratie, om zo gezamenlijk tot de beste oplossing te komen. Maakt dit het traject wat langzamer? Vast en zeker. Maar het startpunt, de enthousiaste docent die een AI learning app ontwikkelt, kan wel voor een snellere start zorgen. En ja, de cultuur binnen de organisatie en (IT-)afdelingen moeten wel zijn ingericht op dergelijke stappen.
Die “schaduw IT” waar Wilfred over schrijft? Dat hoeft helemaal geen schaduw te zijn. In plaats van mensen wegsturen naar hun eigen hoekjes, kun je die experimenten juist onderdeel maken van hoe je als organisatie leert en groeit.
Ambassadeurs, niet eenzame wolven
Je hebt ambassadeurs nodig, mensen die de kar trekken binnen je organisatie. Die laten zien wat er kan, maar tegelijkertijd het enthousiasme geven aan anderen om met z’n allen mee te gaan. Om daar juist gezamenlijk werk van te maken en er niet steeds soloprojecten van te maken.
Denk aan:
Het gaat om gedragsverandering. Hoe zorg je dat je mensen meekrijgt? Toevallig deelt Marco Derksen op LinkedIn een studie uit Denemarken waar blijkt dat de digitale experts in een organisatie niet degenen zijn die voor de digitale transformatie zorgen. Daar zijn anderen voor nodig binnen je organisatie. Sterker nog, de digitale experts hebben maar een beperkte invloed op de verandering in de organisatie. Je hebt elkaar keihard nodig om verder te komen. En je zult dat moeten erkennen van elkaar.
Weg van de cyclus
Mijn hoop zit in die gedragsveranderingen. Als we deze keer met AI de samenwerking wél voor elkaar krijgen, dan kunnen we zo’n enorme organisatorische en intellectuele sprong maken. Echt een grote sprong voorwaarts maken, waar mensen en technologie samenwerken. Daar zijn niet alleen experts voor nodig, maar de mensen in de organisatie die voor de sociale lijm zorgen, met een richtinggevend informeel netwerk.
Zodat we af kunnen van die cyclus “nu kunnen we het eindelijk zelf” gevolgd door “oh wacht, we hebben elkaar toch nodig.” Maar meteen naar die fase waar we elkaar nodig hebben én dat ook weten.
Wilfred’s artikel laat perfect zien waarom individuele docenten-met-AI-apps tegen grenzen aanlopen. De vraag die ik heb: hoe zorgen we ervoor dat organisaties die grenzen niet als probleem zien, maar als uitnodiging om het samen te doen?
Hoe kijken anderen hier naar?
De symbiose van je gedachten, AI en het vertrouwen van de lezer.
In hoeverre laat je AI je gedachten opnieuw herschrijven en wat doet die transparantie met het vertrouwen van de lezer? Ik schrok van mijn eigen gedachten over een professionele kennis van me toen ik zijn tekst las, die deels door AI is geschreven.
Elke week krijg ik de nieuwsbrief van Iskander Smit in mijn inbox, die ik erg graag lees. Hij heeft veel inzichten in de ontwikkelingen van AI en robotica, en hoe zich dat verhoudt tot mensen. Hij duidt de grote technologische bewegingen die we om ons heen zien en voegt daar vaak een filosofische inslag aan toe.
In de laatste editie van zijn nieuwsbrief heeft hij een ’trigger thought’ over GPT-5 en wat er gebeurt met dat model sinds het is uitgekomen. Long story short, mensen zijn niet blij met dat nieuwe model. Hij relateert die backlash voor GPT-5 aan een theorie van Don Ihde: de ‘technological mediation theory’. Ik had er nog nooit van gehoord en vind het super interessant om te lezen hoe we de relatie met technologie ervaren op verschillende niveaus. Iskander geeft duidelijk voorbeelden bij elk niveau zodat je je een voorstelling kunt maken. Zeker het lezen waard.
Ik ben gecharmeerd van Iskander’s manier van schrijven en hoe hij de ideeën uitlegt. Het is op een niveau dat net me net wat meer laat nadenken, herlezen, maar zonder dat het overdreven academisch of vol jargon komt te staan. Op een zeker moment in zijn “Triggered Thought” stuk gaat hij dieper in op zijn eigen gedachten, gebaseerd op een podcast die hij heeft gehoord. Hij verbindt een aantal van die gedachten aan elkaar uit de podcast en de theorie van Ihde. Dat is op zich een heel prettig stuk om te lezen, waar de argumentatie op een intelligente manier wordt opgebouwd.
Maar dan, staat er ineens “As this last sentence is a formulation of my thoughts, expressed by Claude” en verderop in de laatste zin bij de conclusie staat: “It’s already hard to decompose, what of this concluding thought is mine, and what is this symbiosis by Claude?”
Ik voelde me wat voor de gek gehouden.
Dat betekent dus eigenlijk dat een deel van wat hij heeft geschreven, opnieuw is herschreven met zijn prompt, met zijn ideeën. Ik ken Iskander goed genoeg om te weten dat dit wel zijn gedachten zijn en hij is een intelligent denker over technologie en de invloed op onze maatschappij. Maar toch merkte ik dat het iets deed met de waarde die ik gaf aan wat er is geschreven. Voordat ik die zin las, dacht ik: oké, het is allemaal echt heel scherp opgeschreven, heel puntig, heel duidelijk, en ik kan dit volgen. En daarna lees je dat AI daaraan heeft meegeholpen, en dat haalt toch iets van de waarde weg.
Dat verraste me eigenlijk weer, omdat ik juist vind dat AI waarde kan toevoegen en dat het juist allerlei van je gedachten scherper kan maken voor de lezer. De vraag is natuurlijk wel: welke woorden zijn van jezelf, welke woorden zijn van AI? Wat kies je daarin? Wat herschrijf je? Waar schuif je met woorden? Waar breng je je eigen stem weer in? Dat is even zo mijn eerste gedachte toen ik de nieuwsbrief had gelezen.
Wat dan wel transparant is om hier te noemen, is dat alles wat je nu hebt gelezen, heb ik ingesproken in mijn teksteditor via een speech-to-text tooling genaamd Typeless, wat ook weer AI gebruikt. Typeless gebruikt AI om de “euhs” weg te halen uit mijn gesproken zinnen, om dubbele woorden weg te halen en om sommige zinnen in te korten. Daarmee brengt het eigenlijk al wat orde in mijn gedachten. Maar tegelijkertijd, nadat dit allemaal uit Typeless kwam, heb ik alles weer gelezen, heb ik wat stukken herschreven, zijn er een paar zinnen bijgekomen en zijn er woorden weggegaan. Ik voeg zelf de links toe en de opmaak. Dus is het toch wel een symbiose tussen mezelf en AI. De tekst is daarna niet meer door Claude, OpenAI of een ander model herschreven en er zijn geen door AI gegenereerde zinnen toegevoegd.